Autonomous Fuzzing — How We Find Bugs Before Attackers Do
Fuzzing is the art of breaking software by feeding it garbage. Our Autonomous Fuzzing Agent combines LLM-generated test cases with coverage-guided mutation engines to discover vulnerabilities at scale — 1.22 billion executions on wolfSSL, 960+ LLM-crafted seeds, This article explains how it works and why we built it.
What is Fuzzing?
Fuzzing is automated software testing that feeds random or semi-random input to a program and watches for crashes, hangs, or unexpected behaviour. Unlike unit tests (which verify expected behaviour), fuzzing finds bugs by exploring inputs that no human would think to write.
The idea is simple: if you throw enough garbage at a parser, eventually you’ll find an input that makes it do something it shouldn’t. The trick is doing this intelligently — not just random bytes, but mutated inputs that evolve toward deeper code coverage.
The Fuzzing Loop
This loop repeats millions of times per campaign. Each iteration takes microseconds.
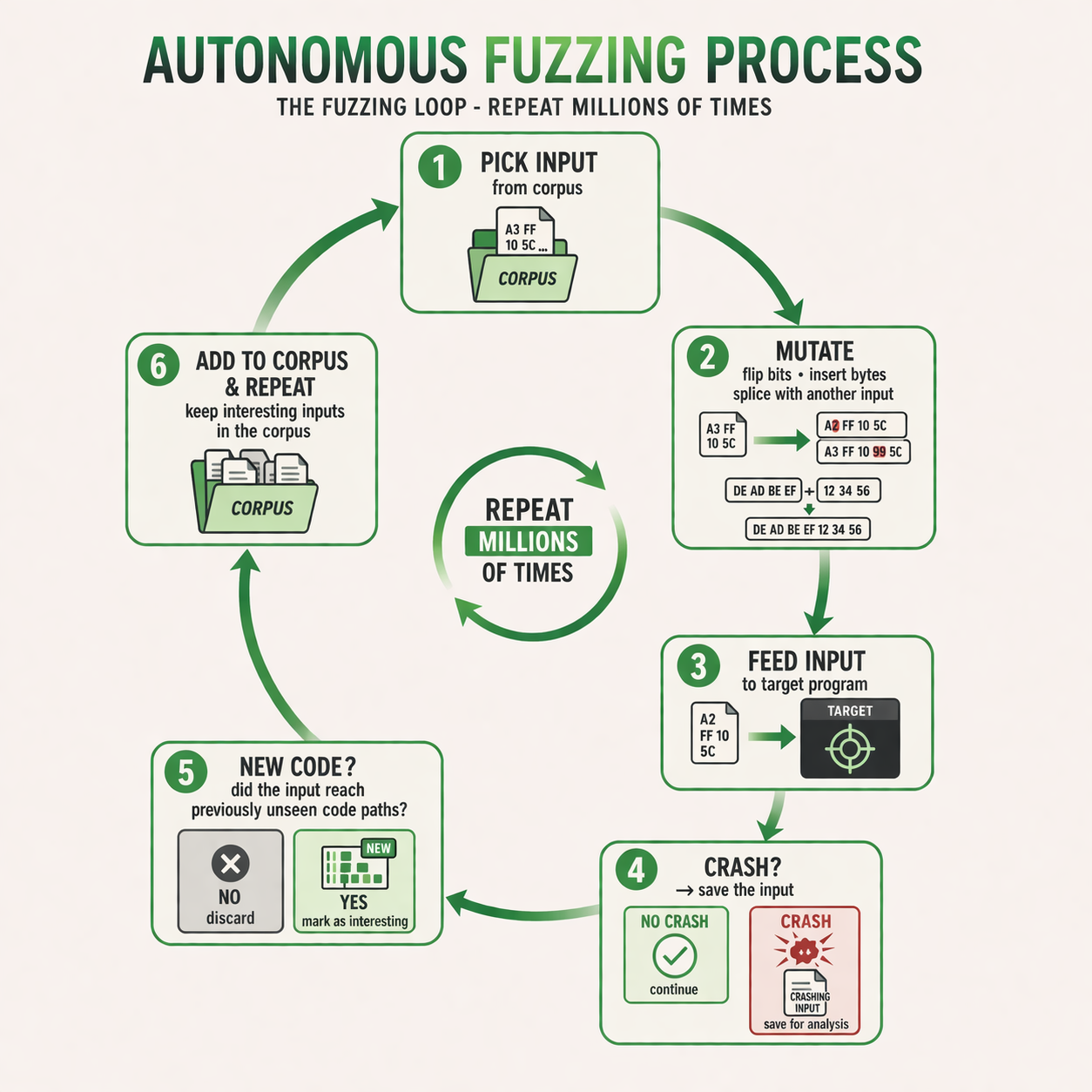
- Pick input from the corpus — select a seed file (raw bytes)
- Mutate — flip bits, insert bytes, splice with another input
- Feed input to the target program — the mutated bytes go into the parser
- Crash? — if the target crashes, save the input for analysis
- New code? — did the input reach previously unseen code paths?
- Add to corpus & repeat — keep interesting inputs for future mutations
Key Concepts
AFL++ (American Fuzzy Lop++)
The fuzzer engine we use. It instruments the target binary at compile time to track which code paths each input exercises, then uses that feedback to evolve inputs toward deeper coverage. 15K–35K exec/sec
ASAN (AddressSanitizer)
Compile-time instrumentation that detects memory errors at runtime: heap overflow, use-after-free, double-free, memory leaks. Runs ~2x slower, so we fuzz fast first, then replay through ASAN.
CMPLOG (Comparison Logging)
Logs every memcmp, strcmp, and integer comparison at runtime.
The fuzzer learns exactly which bytes the program expects and uses them as mutation hints.
4.5x coverage improvement
Seeds & Corpus
Seeds are initial valid inputs (e.g., real certificates for a TLS parser). The corpus grows as the fuzzer discovers inputs that reach new code paths. Starts with ~50 seeds, grows to 500–1,000 items.
Coverage
Percentage of the target’s code that the fuzzer has exercised. <1% means stuck at validation, 1–5% means reaching the parser, >5% is good progress. 3.84% on wolfSSL
Harness
A small C program wrapping the target library function. It’s the bridge between the fuzzer and the code under test. Uses persistent mode for speed.
Our Two-Stage Approach
We separate coverage discovery from crash detection:
Stage 1: Fast Fuzzing
Fuzz with LAF+CMPLOG binary — maximum speed, no ASAN overhead.
The goal is to discover as many code paths as possible and build a large corpus.
35K exec/sec
1.22B executions
Stage 2: ASAN Verification
Replay the entire corpus through the ASAN binary. Any ASAN error is a real memory
safety bug that the fast fuzzer would have silently ignored.
Every crash is real
Where LLMs Come In
Traditional fuzzing starts from seeds and mutates randomly. Our Autonomous Fuzzing Agent adds an LLM layer that generates intelligent seeds — test cases crafted with knowledge of the target protocol’s structure and known vulnerability patterns.
LLM-Augmented Seed Generation
Instead of random bytes, we ask qwen2.5:14b (running locally on a RTX 3060) to generate seeds for specific attack categories:
This is dramatically more effective than random generation because the seeds already have valid protocol structure. The fuzzer only needs to find the specific corruption that triggers a bug.
We use a 3-tier LLM hierarchy to balance speed and cost:
- qwen2.5:14b (local GPU) — primary seed generation, best precision
- dolphin-mistral (local GPU) — creative seeds, complementary failures
- Claude Opus (cloud API) — crash analysis, exploit development, verification
Results
wolfSSL TLS Library
1.22 billion executions
0 crashes (expected — fuzzed by Google OSS-Fuzz since 2016)
3.84% coverage on ASN.1 parser
12 hours, 35K exec/sec on commodity hardware (Ryzen 5)
illustrates a key insight: target selection matters more than tool sophistication. Hardened C libraries with years of continuous fuzzing are very different from PHP web applications that have never been systematically tested.
Protocol-Aware Fuzzing
To fuzz effectively, the engine needs to understand the target protocol. We provide dictionaries — files containing meaningful byte sequences that the fuzzer inserts during mutation:
Without a dictionary, the fuzzer would have to randomly generate these exact byte sequences. With one, it can insert known protocol tokens directly — dramatically accelerating path discovery.
What Makes It Autonomous
The “autonomous” part isn’t just marketing. The agent runs a feedback loop:
- LLM generates seeds based on target analysis and known vulnerability patterns
- Fuzzer runs campaign with LLM seeds as initial corpus
- Anomalies detected — crashes, unexpected status codes, timing differences
- LLM analyses results — triages crashes, suggests new seed categories
- Loop repeats with refined seeds based on what the fuzzer learned
This is different from traditional fuzzing where a human picks seeds, runs a campaign, manually analyses crashes, and decides what to fuzz next. The agent handles the full cycle autonomously, with the LLM providing the “intuition” that would normally require an experienced security researcher.
Scale Context
| Executions | Time (at 35K/sec) | Context |
|---|---|---|
| 1 million | ~30 seconds | Quick sanity check |
| 100 million | ~1 hour | Decent campaign |
| 1 billion | ~8 hours | Thorough assessment |
| 1.22 billion | ~12 hours | Our wolfSSL campaign |
All fuzzing runs on commodity hardware (Ryzen 5 CPU, no GPU needed for the fuzzer itself). LLM seed generation uses the RTX 3060 on our DEV2 server. The Autonomous Fuzzing Agent is part of the HoneyLens research toolkit.